



नेपाली युवाले बनाए सामाजिक सञ्जालका प्रतिक्रिया विश्लेषण गर्ने प्रविधि

पुस २३, २०७६ ११:३६

आफूले सञ्चालन गरेको कम्पनीको विषयमा प्रयोगकर्ता के भनिरहेका छन् ? प्रयोगकर्ताको प्रतिक्रिया कस्तो छ ? यी सबै कुराको अध्ययनका लागि कतिपय कम्पनीले धेरै पैसा खर्च गरिरहेका हुन्छन् ।
तर, त्यसको विकल्प प्रविधिले नै दिने हो भने कस्तो हुन्थ्यो ? यही प्रश्नले उब्जाएको सोच आज यथार्तमा परिणत गर्न रवीन्द्र लम्साल सफल भएका छन् । काठमाडौं विश्वविद्यालयमा पढ्दै गर्दा उनले केही कम्पनीका बारेमा सामाजिक सञ्जालमा व्यक्त प्रतिक्रिया अध्ययन गर्ने माैका पाएका थिए ।
त्यसबेला नै उनले प्रविधिले नै यस्तो काम सहज बनाउन सक्ने संभावनाको खोजि गर्न थालिसकेका थिए । उनि आफैं पनि कम्प्युटर साइन्सका विद्यार्थी भएकाले पनि उनका लागि यो सरोकारको विषय थियो ।
उनले बुझेका थिए, ‘सेन्टीमेन्ट एनालाइसिस’ कुनै नयाँ विषय भने थिएन । ट्रयाडिस्नल मेसिन लर्निङ एल्गोरिदमहरु प्रयोग गरेर धेरै अनुसन्धानकर्ताले यसअघि पनि ‘सेन्टिमेन्ट एनालाइसिस’ मोडल बनाएका थिए । जब सन् २०१४ मा गुगल ले वर्ड भेक्टर (वर्डटुभेक) ल्यायो, त्यसपश्चात कम्प्युटेसन क्षमता अझ बढ्यो । ‘डिप लर्निङ’ बाट ‘नेचुरल ल्याङ्वेज प्रोसेसिङ’ डाेमेनका लागि धेरै एप्लिकेसन आउन थाले ।
‘सेन्टीमेन्ट लाइभ पनि त्यस्तै एउटा डीप लर्निङ प्राेजेक्ट नै हो’, रवीन्द्र भन्छन्, ‘यसको पछाडि एउटा ‘लर्निङ मोडल’ छ । जसले कुनैपनि ‘इन्कमीङ टेक्स्ट’ को सेन्टीमेन्ट पत्ता लगाउँछ ।’ त्यसका लागि हामीले टेक्स्टको सेन्टिमेन्ट स्कोर रेन्ज –१ देखी ० हुँदै +१ सम्म राखिदिएका छौं ।,’ उनि सुनाउँछन, ‘टेक्स्ट सेन्टिमेन्ट स्कोर –१ नजिक हुनु भनेको त्यो टेक्स्ट नेगेटिभ अर्थात नकारात्मक छ । ० को नजिक हुनु भनेको त्यो टेक्स्ट न्युट्रल छ र +१ को नजिक हुनु भनेको त्यो पोजेटिभ अर्थात सकारात्मक हो ।’

हाल यो परियोजना प्री–अल्फा चरणमै छ । अहिले यसले ट्वीटरको मात्रै ‘रियल टाइम न्युजफिड मनिटर’ (न्युजफिडको तुरुन्ता तुरुन्तै मापन तथा अनुगमन) गर्छ । ट्वीटरमा कुनै पनि कि वर्डका आधारमा कम्पनीले आफ्नो उत्पादन तथा सेवाको बारेमा प्रयोगकर्ताले के भन्दै छन् ? उनिहरुको राय के छ ? भन्ने कुरा पत्ता लगाउन यसले मद्दत गर्छ । अहिले यसलाई विस्तार गर्नेकाममा रवीन्द्र लागिरहेका छन्। ‘रेड्डीट र गुगल न्युजमा समेत काम गर्ने गरी यसको विकास गरिरहेका छौँ,’ उनी भन्छन् ।
यो मोडलले तीन खण्डमा जानकारी दिन्छ । पहिलो खण्डमा भर्खरै गरिएका एक हजार ट्वीटको ‘सेन्टीमेन्ट प्याटर्न देखाउने उनको भनाई छ । दोस्रो खण्डमा हालसम्म प्रयोगकर्ताले देखाएको प्रतिक्रिया देखाउँछ । जसमा मनिटर गर्न सुरु गरिएको दिन देखी हालसम्म कस्तो प्रतिक्रिया आएको छ, त्यसको जानकारी लिन सकिन्छ भने, तेस्रो खण्ड ‘पाई प्लट’ हो । रवीन्द्रका अनुसार त्यसमा हालसम्म कति ट्वीट समावेश गरिएका छन् भन्ने देखाउँछ ।
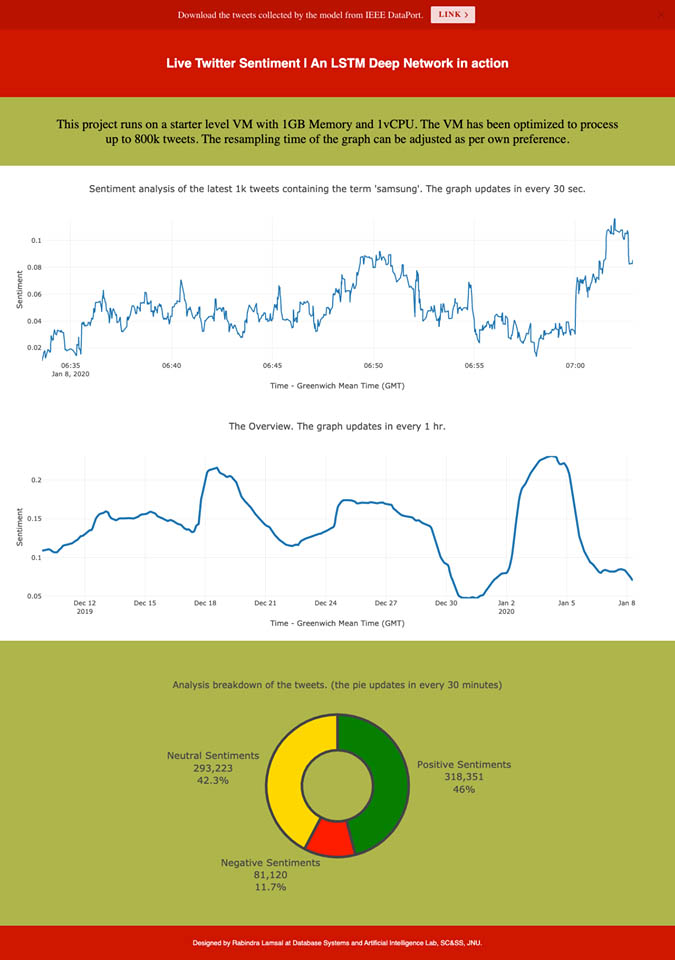
यी तीनै खण्डमा तपाईंले आफूलाई पायक पर्ने गरि ट्वीटको मापन गर्न पनि सक्नुहुन्छ । दोस्रो खण्डमा पनि तपाईंले कम्पनीले हालसम्म गरेको ट्वीट अवथा पछिल्लो एक घण्टाभित्र भएको ट्विटको मात्रै पनि मनिटर गर्न सक्नुहुन्छ ।
त्यसकालगि प्राेजेक्टलाई अधिकतम ‘अप्टिमाइज’ गरिएको छ । हाल यो प्रोजेक्ट १ जीबी र्याम र १ भी सीपीयु को क्लाउड सर्भरमा सञ्चालन भइरहेको छ । माइक्रोसफ्ट र गिटहवको अनुदानमा परियोजनाका लागि आवश्यक श्रोत जुटाइएको उनले सुनाए ।
त्यसैले यसलाई जो कोहिले पनि आफ्नो ल्यापटप तथा कम्प्युटरमा सहजै प्रयोग गर्न सकिने उनको भनाई छ । ‘यसका लागि प्रयोगकर्ता कुनै डेटाको विषयमा जानकार तथा प्राविधिक पृष्ठभूमीको हुन जरुरी छैन’, रवीन्द्र भन्छन्, ‘ब्राउजरबाटै सबै जानकारी लिन सकिन्छ । त्यसैले यसका लागि थप कुनै एप इन्स्टल गरिराख्नु पनि पर्दैन ।’
कसरी भएको थियो यो परियोजनामा काम
यो प्रविधि विकासको सुरुवात जवाहरलाल नेहरु विश्वविद्यालयबाट भएको हो । काठमाडौं विश्वविद्यालयमा कम्प्युटर साइन्समा स्नातक सकेपछि उनी जवाहरलाल नेहरु विश्वविद्यालयले पुगे । त्यहाँ उनी स्कुल अफ कम्प्युटर एण्ड सिस्टम साइन्समा भर्ना भए । अनि उनको भेट प्रोफेसर टीभी विजय कुमारसँग भयो ।
टीभी जेएनयुको डाटावेश सिस्टम तथा आर्टिफिसियल इन्टेलिजेन्स ल्यावमा एक ‘डिज्यास्टर रिस्पोन्स सिस्टम’ को डिजाइनमा काम गरिरहेका थिए । सोही सिस्टम निमार्णमा रवीन्द्रले पनि जोडिनै मौका पाए । उनि सम्झिन्छन् । त्यसबेला भर्खरै नेपालमा महाभुकम्प गएको थियो ।

त्यसैले उक्त प्रोजेक्टमा जोडिन पाउँदा रवीन्द्र हौसिएका थिए । ‘हामीले सामाजिक सञ्जालमा राखिएका पोष्टहरुलाई प्रयोग गरेर त्यसबाट तत्कालै कुनै जानकारी निकाल्न सकिन्छ कि भनेर अध्ययन गर्न थाल्यौं । नभन्दै अध्ययनका क्रममा पाइयो । हाइटी लगायतका देशमा सामाजिक सञ्जालका म्यासेज प्रयोग गरेर प्रकोप पछिको प्रतिक्रिया विश्लेषण गरिएको फेला पार्यौं ।’
त्यसको एक वर्षपछि सिस्टमको एउटा प्रोटोटाइप बन्यो । त्यसले आएको टेक्सलाई विभिन्न सात विधामा वर्गीकरण गर्दथ्यो । जसमा पूर्वाधारको क्षति, घाइते तथा मृत्यु भएका मानिस, हराएका तथा भेटिएका मानिस, सहयोगको आवश्यकता र स्वयम् सेवक, विस्थापित भएका मानिस, रोग र सबैभन्दा बढी क्षति भएको ठाउँ भनेर त्यसको वर्गीकरण गरिएको थियो ।
यीमध्ये कुनै पनि एक विधाको ट्वीटलाई लिएर सबैभन्दा बढी प्रभाव कहाँ परेको छ ? कति क्षति भएको छ ? जस्ता विषयहरु पत्ता लगाउन सक्थ्यो । त्यसैका आधारमा तत्कालै उक्त स्थानमा प्रहरी परिचालन गर्न र प्रभावितलाई आवश्यक सहायता पुर्याउन सहज हुने भयो ।
यसको निमार्ण नेपाल र भारतलाई मिल्ने गरि बनाइएको थियो । यो बनाउँदा धेरै चुनौति पनि खेप्नुपरेको रवीन्द्र सम्झिन्छन् । ‘नेपाल र भारतमा धेरै ट्वीट रोमानाइज्ड स्क्रिप्टमा लेखिने भएकाले त्यसमा फेरी काम गर्नुपर्ने भयो । त्यसका लागि हामीले रोमनाइज्ड स्क्रिप्टमा भएको ट्वीटलाई सुरुमा मात्री भाषामा र त्यसपश्चात अंग्रेजी भाषामा परिवर्तन गर्ने सिस्टमको विकास गर्यौं ।’
रोमनाइज्ड ट्वीटलाई मातृभाषामा र त्यसपश्चात अंग्रेजी भाषामा परिवर्तन गर्ने सिस्टम त बन्यो तर नेपाली शब्दकोष भने थिएन । नेपाली भाषालाई प्रभावकारी बनाउन नेपाली भाषाको शब्दकोष बनाउनु पर्नेभयो । नेपाली मिडियामा लेखिने र अन्य विभिन्न माध्ययमको प्रयोग गरि १० करोड नेपाली शब्द भएको टेक्स्ट कर्पोरा बन्यो ।
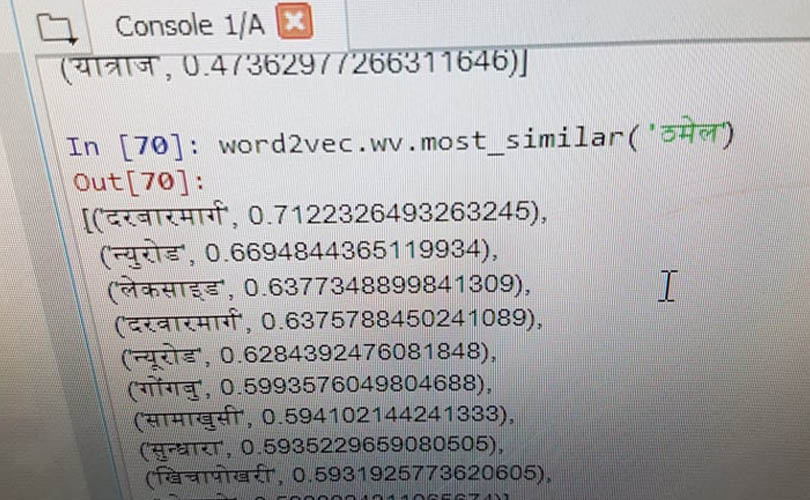
जसको प्रयोगले पाँच लाख भन्दा बढी नेपाली शब्द र वाक्यको लागि तीन सय विभिन्न आयामिक शब्द बनाएर भेक्टरलाई उपलब्ध गराउने काम भएको रवीन्द्रले जानकारी गराए । उदाहरणका लागि पर्यटन, विकास, उद्योग, सूचना प्रविधि आयामीक शब्द भयो । यदि तपाईंले ‘ठमेल’ भनेर सर्च गर्नु भयो भने ठमेल नेपालको पर्यटकीय क्षेत्र भएको हिसाबले पर्यटनसँग सम्बन्धीत स्थानहरु जस्तै पोखरा, ठमेल वरीपरिका अन्य क्षेत्र, चितवन लगाएतका स्थान देखाउने ।
नेपाल टेलिकम, एनसेल जस्ता कम्पनीले पनि यसलाई आफ्नो सर्भरमा राख्न सक्ने रवीन्द्रको भनाई छ । ताकि आपतविपतको समयमा तुरुन्तै प्रतिक्रिया जनाउन सकियोस् । उनी भन्छन्, ‘भूकम्पको समयमा इन्टरनेट सेवाको निरन्तरतामा समस्या हुनसक्छ । त्यस्तो समयमा दुरसञ्चार सेवा प्रदायकले आफ्नो सर्भरमा यस्तो प्रणली इन्सटल गर्ने हो भने तत्कालै भुकम्प प्रभावको विषयमा जानकारी लिन सक्छन् ।
डिज्यास्टर रिस्पोन्स सिस्टमको प्राटोटाइप बनाइसकेपछि उनको टिमलाई थोरै क्षमताको कम्प्युटरमा पनि कति सम्मको ट्वीटको डाटा एनालइस गर्न सकिन्छ भनेर परीक्षण गर्नुपर्ने आवश्यकता थियो । त्यसैको परिणाममा आधारित ‘सेन्टिमेन्ट’ बन्यो ।
परीक्षण गर्दै जाँदा एक जीब र्याम तथा १भी सीपीयू भएको कम्प्युटरले पनि ८ लाख ट्वीटलाई प्रोसेस गर्न सफल भयो । ट्वीटको संकलनको समयलाई तलमाथि गरेर सर्भरको क्षमता घटाउन बढाउन पनि सकिने रवीन्द्र बताउँछन् ।

‘सेन्टिमेन्ट सुरुमा एउटा साइड प्राेजेक्टको रुपमा सुरु गरिएको थियो’, उनी भन्छन्, ‘बजारमा यसको आवश्यकता देखियो ।’
यसले डेटासँग सम्बन्धित अन्तर्राष्ट्रिय संस्था आईईईई डेटापोर्टले २०१९ को बेष्ट डेटासेटको सम्मान पनि प्राप्त गरेको छ । त्यसपछि भने यो प्रविधिको माग बढ्दै गएको छ । माग बढेसँगै २०२० को मार्चसम्ममा यसलाई अपोन–सोर्सको रुपमा ल्याउने योजना बनेको रवीन्द्रले जानकारी दिए ।
पछिल्लो अध्यावधिक: असोज २, २०७९ २२:३०





















